

GitHub Actions 101: Deep Dive into Workflow Attributes
Beginner Series to Automating your Workflow with GitHub Actions! Part 2: Useful Attributes to Know


Hello and welcome to Part 2 of the GitHub Actions series. A series where we will walk through everything you need to know about GitHub Actions, from the basics to creating your own customized workflow.
If you have missed Part 1, please read it here before proceeding to Part 2.
In this part, let's dive deeper into some attributes and useful things you need to know to customize a good workflow.
Job dependencies
Recap: Each workflow must have 1 job, each job has a unique identifier, they run in parallel by default.
As discussed in the previous part of this series, jobs are executed in parallel by default. In the example below, job1 and job2 will be run simultaneously.
jobs:
job1: # unique identifier
# job stuff here
job2: # unique identifier
# job stuff here
However, using theneeds attribute, we can ensure certain jobs to run based on another job.
Let's take a look at an example:
jobs:
job1:
job2:
needs: job1
job3:
needs: [job1, job2]
As seen in the example, job1 must complete successfully before job2 can run. This means that if job1 fails, then job2 would not run. Furthermore, since job3 depends on job1 and job2, it will not run if both jobs fail.
Sequential Jobs Regardless of Success
What if you need a workflow that runs jobs in a certain order but do not require job1 to be successful to run job2?
We can pass a conditional with the if attribute. The value will be always() which tells job2 to always run after job1, despite the result of its run.
jobs:
job1:
job2:
if: always()
needs: job1
Conditionals
Since we discussed if earlier, let's take a closer look at conditionals in GitHub Actions. These can be very useful when trying to build a custom workflow with different conditions.
As you may have recalled from Part 1 of this series, the top-most attribute we include in our workflow is the on attribute. This attribute must be included in any workflow because it indicates what event will trigger the workflow to run.
Most common events you will see are push, pull_request and release. For example:
on:
push:
branches:
- master
pull_request:
branches:
- develop
release:
Notice that I use the branches attribute as conditionals, where the workflow will run if a push is on the master branch; or where the workflow will run if a pull_request is on the develop branch. Hence, the workflow will run only when these certain conditions are met.
Instead of branches, we can also use branches-ignore to exclude certain branches from the event trigger.
Note: You cannot use branches and branches-ignore under the same event of a workflow (YAML) file. Also applies to tags and tags-ignore attributes.
on:
push:
branches-ignore:
# Do not push events to branches matching refs/heads/mona/octocat
- 'mona/octocat'
# Do not push events to branches matching refs/heads/releases/beta/3-alpha
- 'releases/**-alpha'
tags-ignore:
- v1.* # Do not push events to tags v1.0, v1.1, and v1.9
Code from docs.github.com/en/actions/reference/workfl..
Environment Variables
Most of you would be familiar with this term. Environment variables refer to dynamic key-value pairs that are stored in memory on the virtual environment that the workflow is run on.
Some key points to note about environment variables:
- They are case-sensitive
- They can be set in the workflow, jobs or steps
- They are injected and read as the job runs, before commands are called
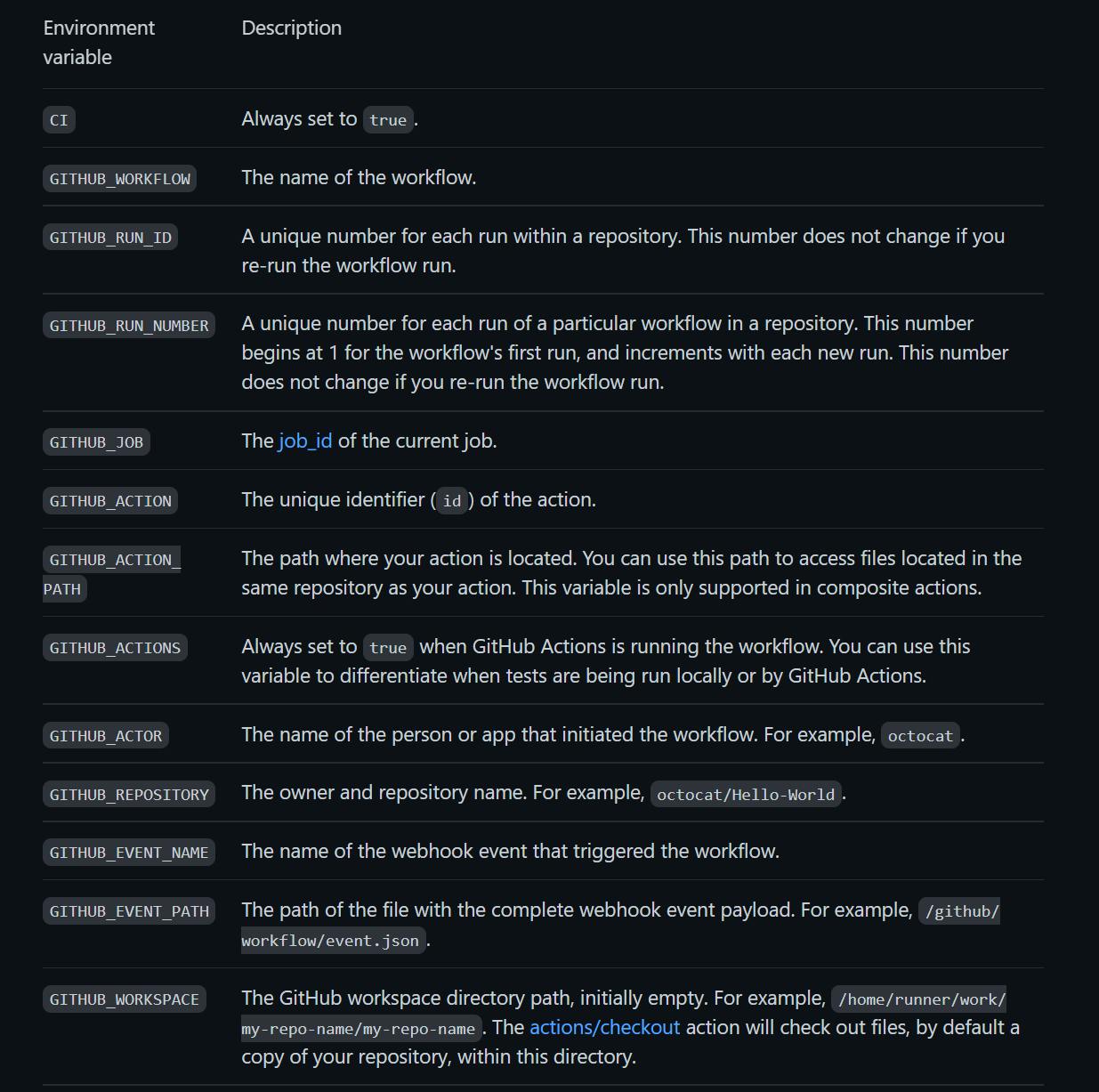
GitHub has some default environment variables, which are recommended to use to access the file system and run across any runner environment. Here are some of them:
Create custom variables
Environment variables other than ones provided by default can be created in the workflow, jobs or steps using the env attribute.
For example, I have created a simple workflow with custom variables in the 3 different areas below. To access or read the variables, you can either the shell syntax of the runner environment or the YAML syntax.
In my example, the environment of my runner is Ubuntu so in bash, to read the variable is simply $VARIABLE_NAME. For Windows, it would be $env:VARIABLE_NAME.
The YAML syntax would work in any environment. It would be ${{ env.VARIABLE_NAME }}.
Note: Good naming convention to keep environment variables all caps with underscores as spaces.
name: EnvVar Tutorial
env: # you can set environment variables in the workflow
WORKFLOW_VARIABLE: "Workflow variables can be accessed anywhere in the workflow!"
on:
push:
branches: [ main ]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
env: # env var can be set in a job too, can only be accessed within the job itself
JOB_VARIABLE: "This is my Job variable!!!!!!!"
steps:
- name: prints the environment variables
env: # setting env var in a step means only the step can access it
STEP_VARIABLE: "Example step variable....................."
run: |
echo Here are my custom environment variables
echo $WORKFLOW_VARIABLE
echo $JOB_VARIABLE
echo $STEP_VARIABLE
Now let's run this workflow and see the results:
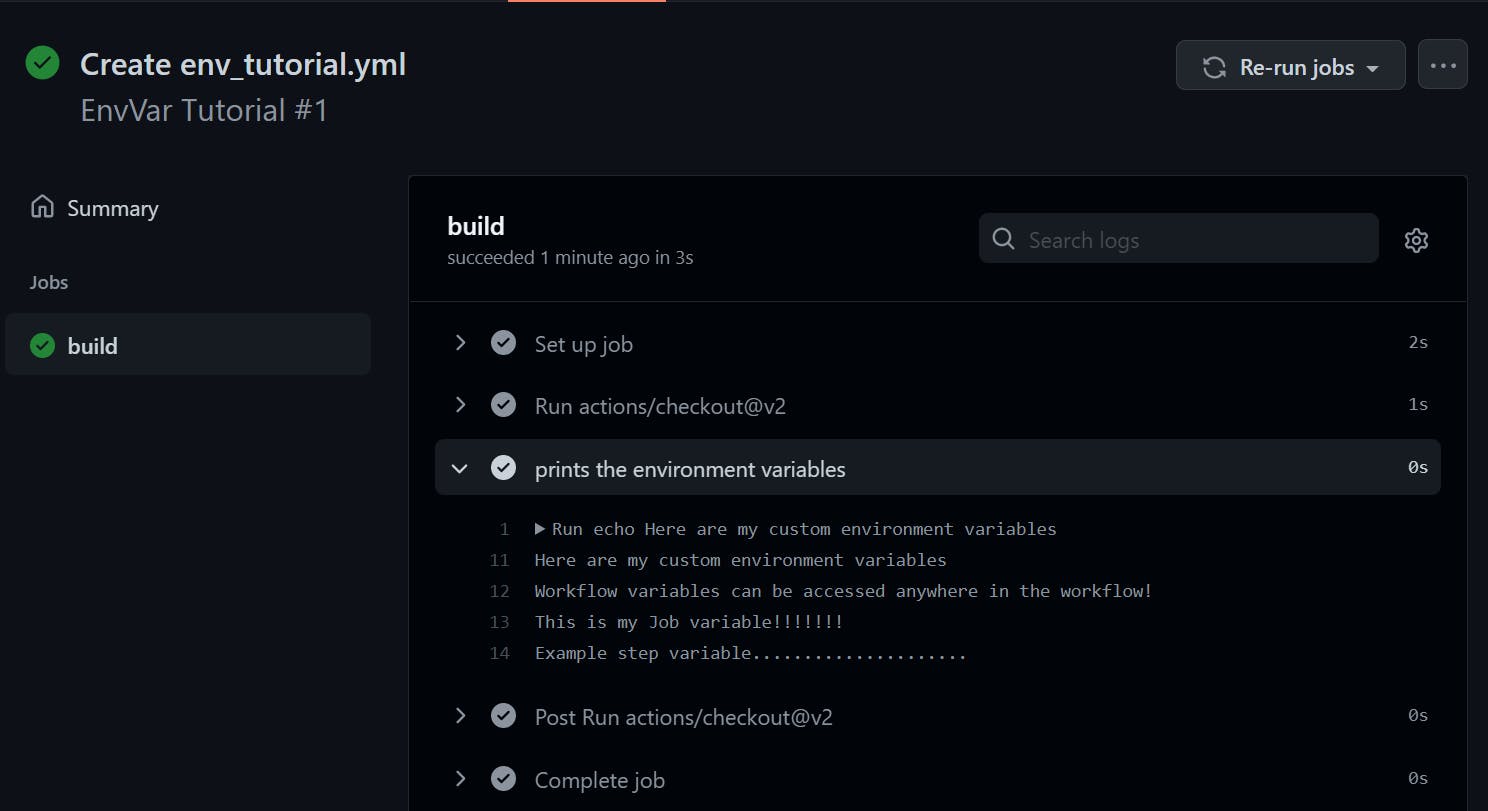
It has perfectly printed out our custom variables!
To be Continued
There is still much more to learn about GitHub Actions. Let's stop here for today. Please visit this repo to review what we have built today.
Thanks for reading part 2! I hope it has been a helpful read. Please leave any questions or comments below. Don't forget to like and share the article if it helps you in any way.
Let's meet again in part 3, where we will take a closer look at actions. Feel free to read the provided documentation in the References section below. Cheers!